让手机跑SOTA模型快8倍!Facebook AI开源最强全栈视频库:PyTorchVideo!
编辑按:本文转载至微信公众号 “新智元”,贝壳投研经授发布
时隔一年,Facebook AI携PyTorchVideo重回视频理解的战场。其不仅可以「无缝」接入各类代码库,甚至还「略懂」LeCun最爱的自监督学习。顺便一提,手机也能玩!
视频已逐渐超过文字和图片,可以说成为了现在使用最广的媒体形式,同时也占据了用户更多的浏览时间,这就使得视频理解变得尤为重要。
各大互联网公司与顶尖高校纷纷绞尽脑汁,竞相研究SOTA的视频理解模型与算法
在谷歌,脸书,Open-MM Lab等分别祭出各家杀器之后,脸书人工智能实验室(Facebook AI)在推出PySlowFast之后时隔一年,携PyTorchVideo重回战场。


官方网站: https://pytorchvideo.org/
今天我们就来扒一下,PyTorchVideo究竟是怎样的一个代码库,又如何能在开源当天就跻身于GitHub Trending榜单。
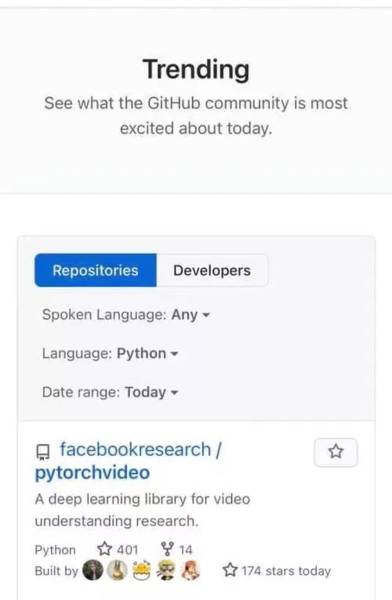
PyTorchVideo哪儿都能用
不同于在座的各位视频代码理解框架只醉心于自家框架,无法移步与其他代码库
PyTorchVideo像是torchvision等基础代码库一般,「哪儿都能用」!PyTorchVideo不但可以用在视频理解任务中,甚至可以用在其他任务的代码库。
脸书人工智能实验室的大佬们不但在「自家人」的PySlowFast代码库上无缝使用上了PyTorchVideo,并且还在Classy Vision,PyTorch Lightening等等框架上无缝插入。
作为含着金钥匙出生的PyTorchVideo,其直接成为了PyTorch Lightning-Flash的视频理解担当,作为基础库被默认使用。
这不,在FiftyOne项目中,开源社区的吃瓜群众就利用Lightning-Flash搞出了一个浏览视频的工具箱,可以直接查看视频的动作类别。
FiftyOne: https://medium.com/pytorch/ushering-in-the-new-age-of-video-understanding-with-pytorch-1d85078e8015
PyTorchVideo啥都能做
更厉害的是,PyTorchVideo似乎「啥都能做」!不但在视频分类,动作检测等任务中深耕SOTA。
甚至还「略懂」LeCun最爱的自监督学习,以及音频事件检测等等千奇百怪的任务也不在话下。
基于PyTorchVideo的SlowFast模型进行动作监测
PyTorchVideo手机也能玩
更丧心病狂的是,PyTorchVideo一并开源了移动端的加速优化,不但提供了手把手的教程,将视频模型一步步优化核心Kernel,量化(quantilize)加速。
数倍加速后在移动端实时运行,甚至官方直接暴力放出Android和iOS移动端开源代码,将SOTA的视频模型直接塞到手机里跑着玩玩。
在三星Galaxy S10手机上运行的PyTorchVideo加速X3D模型,运行速度快8倍,处理一秒视频大约需要130毫秒
PyTorchVideo是个啥
PyTorchVideo的真身是一个视频理解的机器学习库,可以服务于各种代码库,以及各类SOTA视频模型模型和开源视频模型。
以及各种视频基础算法,视频数据操作,各类流行视频数据集,视频增广,视频模型加速量化,等等一些列的全栈视频相关内容。
PyTorchVideo怎么玩首先pip一下
pip install pytorchvideo然后,在浏览官方的教程并上手实验了一下之后,发现通过PyTorchVideo只需要寥寥几行就可以训练一个视频模型:
frompytorchvideo import data, models, accelerator# Create visual and acoustic models.visual_model = models.slowfast.create_slowfast(model_num_class=400,)acoustic_model = models.resnet.create_acoustic_resnet(model_num_class=400,)# Create Kinetics data loader.kinetics_loader = torch.utils.data.DataLoader(data.Kinetics(data_path=DATA_PATH,clip_sampler=data.make_clip_sampler("uniform",CLIP_DURATION,),)batch_size=BATCH_SIZE,)# Deploy model.visual_net_inst_deploy = accelerator.deployment.\convert_to_deployable_form(net_inst, input_tensor)
那么从开源的训练模型库中直接使用模型效果如何?
model = torch.hub.load("facebookresearch/pytorchvideo", model=model_name, pretrained=True)
官方的模型库太丰富,简直眼花缭乱。
Kinetics-400
arch | depth | frame length x sample rate | top 1 | Flops (G) x views | Params (M) |
C2D | R50 | 8x8 | 71.46 | 25.89 x 3 x 10 | 24.33 |
I3D | R50 | 8x8 | 73.27 | 37.53 x 3 x 10 | 28.04 |
Slow | R50 | 4x16 | 72.40 | 27.55 x 3 x 10 | 32.45 |
Slow | R50 | 8x8 | 74.58 | 54.52 x 3 x 10 | 32.45 |
SlowFast | R50 | 4x16 | 75.34 | 36.69 x 3 x 10 | 34.48 |
SlowFast | R50 | 8x8 | 76.94 | 65.71 x 3 x 10 | 34.57 |
SlowFast | R101 | 8x8 | 77.90 | 127.20 x 3 x 10 | 62.83 |
SlowFast | R101 | 16x8 | 78.70 | 215.61 x 3 x 10 | 53.77 |
CSN | R101 | 32x2 | 77.00 | 75.62 x 3 x 10 | 22.21 |
R(2+1)D | R50 | 16x4 | 76.01 | 76.45 x 3 x 10 | 28.11 |
X3D | XS | 4x12 | 69.12 | 0.91 x 3 x 10 | 3.79 |
X3D | S | 13x6 | 73.33 | 2.96 x 3 x 10 | 3.79 |
X3D | M | 16x5 | 75.94 | 6.72 x 3 x 10 | 3.79 |
X3D | L | 16x5 | 77.44 | 26.64 x 3 x 10 | 6.15 |
Something-Something V2
arch | depth | pretrain | frame length x sample rate | top 1 | Flops (G) x views | Params (M) |
Slow | R50 | Kinetics 400 | 8x8 | 60.04 | 55.10 x 3 x 1 | 31.96 |
SlowFast | R50 | Kinetics 400 | 8x8 | 61.68 | 66.60 x 3 x 1 | 34.04 |
Charades
arch | depth | pretrain | frame length x sample rate | MAP | Flops (G) x views | Params (M) |
Slow | R50 | Kinetics 400 | 8x8 | 34.72 | 55.10 x 3 x 10 | 31.96 |
SlowFast | R50 | Kinetics 400 | 8x8 | 37.24 | 66.60 x 3 x 10 | 34.00 |
AVA (V2.2)
arch | depth | pretrain | frame length x sample rate | MAP | Params (M) |
Slow | R50 | Kinetics 400 | 4x16 | 19.5 | 31.78 |
SlowFast | R50 | Kinetics 400 | 8x8 | 24.67 | 33.82 |
甚至通过PyTorchVideo加持的 Lightning Flash,分类视频仅仅只需三行。
from flash import VideoClassifier
model = VideoClassifier.load_from_checkpoint("checkpoint_uri")model.predict("path_to_video_folder")
据官方博客透露,PyTorchVideo开源了一大票视频模型,包括脸书人工智能实验室近期出现在ICCV,ICML等工作:
Multiscale Vision Transformers
https://arxiv.org/abs/2104.11227
A large-scale study on unsupervised spatiotemporal representation learning
https://arxiv.org/abs/2104.14558
Multiview pseudo-labeling for semi-supervised learning from video
https://arxiv.org/abs/2104.00682
Is space-time attention all you need for video understanding?
https://arxiv.org/abs/2102.05095
Keeping Your Eye on the Ball: Trajectory Attention in Video Transformers
https://arxiv.org/abs/2106.05392
SlowFast networks for video recognition
https://arxiv.org/abs/1812.03982
X3D: Expanding architectures for efficient video recognition
https://arxiv.org/abs/2004.04730
Audiovisual SlowFast networks for video recognition
https://arxiv.org/abs/2001.08740
Non-local neural networks
https://arxiv.org/abs/1711.07971
A closer look at spatiotemporal convolutions for action recognition
https://arxiv.org/abs/1711.11248
Video classification with channel-separated convolutional networks
https://arxiv.org/abs/1904.02811
似乎MultiScale Vision Transform也位列其中,有兴趣的朋友可以去一探究竟。
飞鲸投研从多维度分析,整理了一份《成长50》的名单,可以关注同名公众号:"飞鲸投研":feijingtouyan,进行领取(点击复制)
/阅读下一篇/
绍球谈股:A股完美承接,继续加仓!















脱水研报
-
华东医药股份有限公司创建于1993年,总部位于浙江杭州,公司分三大主营业务,医药工业、医药商业和医美产业,以医药工业为主导,全产业链覆盖,多环节协同。据国金证券
-
公司专注于数模混合、模拟、射频等芯片,产品型号达470余款,2020年产品销量约32亿颗,手机领域应用占比85%。据国金证券研报分析,近几年公司在音频功放、电源
-
金博股份创立于2005年,脱胎于中南大学粉末冶金工程研究中心,从民用碳基复合材料起步,2011年突破了大尺寸的碳碳材料制备技术,相较同行有近10年的先发优势,充
-
近日,康泰生物全资子公司民海生物的13价肺炎球菌多糖结合疫苗已正式获批,成为国产第二款获批的13价肺炎疫苗。民海生物自主研发的13价肺炎球菌多糖结合疫苗为全球首
-
公司设立以来一直从事半导体设计和分销业务,2019年公司完成了收购北京豪威及思比科的重大业务重组事项,完成收购后CIS成为公司核心业务与增长驱动力,公司切入光学




名家观点
-
一隐秀路大佬就是这波主多南天的主力,今天下午又再度拉回,从同花顺超级盘口看它从水下一路点火,要不是大盘太弱了大概率能走出地天,上次也是在一片绝望中隐秀路大佬引导
-
这一周的弱势,始于外资的大幅出逃,不过,周五的弱势,却怪不了人家,参考下北上资金,尽管深港通有一定流出,但也谈不上很大,沪港通更是流入的,所以,周五的弱,纯属于
-
以岭药业:这个票近期是一路小快步上行,到了今天终于是走了加速,明天溢价问题不大,但周四涨停也说明短线资金进来了,短期估计短线资金还会关注这里,明天预计冲高问题不
-
10月份已到了最后几天,三季报也进入到了最后的集中披露,而这个时候,就要注意下不及预期的雷股了。怎么规避不及预期的可能雷股?如果对个股基本面不是很了解,还真没什
-
第二段,就是11点之后,不管是中午前的强反击,还是午后的回落,以及随后的僵持,跟北上资金的节奏几乎完全同步了,这意味着,多空双方都选择了观望,然后,才有了北上资





热点题材
-
点评:毫米波拥有更为丰富的频谱资源,这对进一步提升5G连接速度,充分释放5G应用的潜能至关重要。所以产业界早已明确了毫米波将是未来5G的演进方向。我国国内各大运
-
昇腾芯片是2019年华为公司发布的人工智能处理器,包括昇腾910和昇腾310处理器,采用自家的达芬奇架构。昇腾910支持全场景人工智能应用,而昇腾310主要用在
-
点评:减少碳排放、增加碳吸收是实现碳达峰、碳中和的两大主要方向。碳捕捉位于CCUS全产业链上游,目前依然在成本高、成果小的早期阶段。我国目前仅部署10个全流程
-
据统计,欧洲天然气现货价格指数已较去年同期上涨近7倍,美国天然气期货合约价格达到近十年新高。国泰君安孙羲昱认为,全球碳中和背景是推升天然气价格的重要因素。因燃煤
-
点评:国家“十四五”规划中已经将全国有线电视网络整合与广电5G一体化列为了重点任务工程(项目),而深度整合则正式成为了中国广电、广电股份公司的下一阶段重点推进工





最新资讯
-
价格的变动反映着背后供求关系的变化,价格回升往往预示着行业景气度的回升,在这个时候,挖掘有潜力的行业和公司尤为重要。我国蛋氨酸现阶段正处于成长期,国产化替代加速
-
从机构调研数量看,排名靠前的迈瑞医疗、联影医疗、澳华内镜,都属于医药行业。汽配行业中,三花智控的关注度是最高的,2023-2024年接待机构近一千家,堪称A股的
-
究其原因,一是大环境推动,二是其下游覆盖领域多,前景广阔。数据显示,2023年中国低空经济市场达到50亿元,预计到2026年将突破万亿。低空飞行与产业融合,是低
-
就在4月27日,“天工”机器人震撼亮相。这是北京人形机器人创新中心推出的产品,由小米机器人、优必选科技等参投。从实际表现看,“天工”机器人并不逊于马斯克的擎天柱
-
其所选投资标的,往往是未来确定性比较高的。数据显示,截至2023年12月31日,在70多家上市中药企中,社保基金一共投资了12家公司。其中,市值现在百亿以上的有