颜水成团队又出王炸!不需要额外数据,Transformers超越CNN问鼎ImageNet
编辑按:本文转载至微信公众号 “新智元”,贝壳投研经授发布
今年年初,原依图科技的CTO颜水成博士离职后,加入了东南亚电商平台Shopee
Shopee是东南亚及中国台湾的电商平台 ,该公司于2009年由李小冬(Forrest Li,中国大陆天津人)创立,发迹中国目前已扩展到马来西亚、泰国、印度尼西亚、越南、菲律宾和中国台湾,为全世界华人地区用户的在线购物和销售商品提供服务。
当时Shopee的母公司冬海集团公布财报,公告除了披露了公司2020的财务情况,也特别确认了颜水成的加入。
其中还显示,颜水成博士担任集团首席科学家,其中还特别提到,颜博士将建设和领导Sea人工智能实验室。

如今Sea AI Lab的研究成果来了!
一出手就是王炸,把以往需要吞噬海量数据才能超越CNN模型的Visual Transformers抬到了新高度!
不需要额外数据,Transformers超越CNN问鼎ImageNet!

多年来,视觉识别一直是卷积神经网络(CNNs)的天下。
但随着基于自注意的视觉Transformers(pre-ViTs)的问世,模型在 ImageNet 分类任务中已经取得了很大的发展,但如果在没有提供额外数据的情况下,其性能仍然不如最新的 SOTA CNN 模型。
基于这个想法,他们的目标是弥补CNN和ViT之间由数据产生的性能差距,并证明基于注意力的模型确实能够胜过CNN。
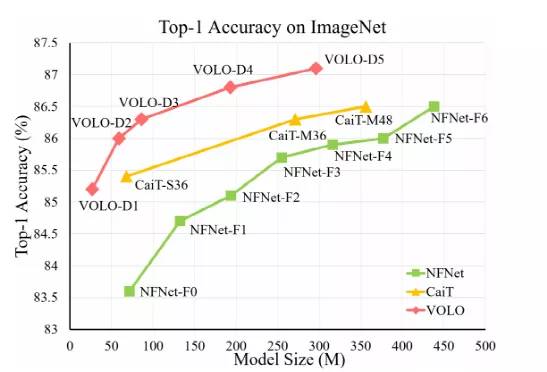
研究人员发现,限制 ViTs 在 ImageNet 分类中的性能的主要因素是它们在将精细级别的特征编码到词表示中的效率低。
为了解决这个问题,文中介绍了一种新颖的前景(outlook)注意力,并提出了一种简单而通用的体系结构——视觉前瞻器( Vision Outlooker, VOLO)。
与自我注意不同,outlook 的注意力集中在粗糙的全局去频率建模上,能够有效地将更精细的特征和上下文编码成标记,这些标记对于识别性能非常重要,但是自我注意却很大程度上忽略了它们。
实验表明,VOLO 在没有使用任何额外训练数据的情况下,达到了87.1% 的top1精度 ImageNet-1K 分类,是第一个在这个竞争性基准上超过87% 精度的模型。
此外,预训练的volo 可以很好地转移到下游任务中,例如语义分割。在ADE20k 验证集上获得了84.3% 的 mIoU 分数,在 ADE20K 价值集上获得了54.3% 的分数。
论文中的代码已经上传到GitHub上。
文中的模型可以看作是两个分开的阶段
第一阶段由一堆outlooker组成,这些outlooker生成精细级别的token表示。这个第二阶段部署一系列Transformer block聚合全局信息。
在每个阶段的开始,利用贴片嵌入模块对输入进行映射用设计好的shape来表示。
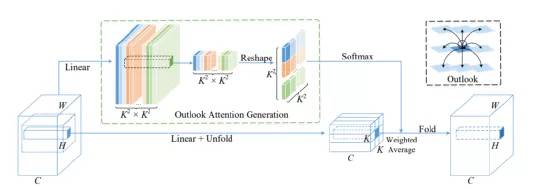
Outlooker由一个outlook注意层组成,空间信息编码与多层感知器(MLP)用于通道间信息交互。

LN指的是Layer Normalization
对比Transformer和CNN,前景注意力通过对空间信息进行编码,通过测量符号表示对之间的相似性,参数学习比卷积更有效。
其次,注意力采用滑动窗口机制在精细级别对token表示进行局部编码,并在视觉任务上某种程度上保留了关键的位置信息。
第三,产生注意权重的方法简单有效。不像自我注意力这依赖于query-key矩阵乘法,outlook的权重可以直接产生一个简单的整形操作,节省计算。
论文的第一作者袁粒(Li Yuan)来自新加坡国立大学。
据悉,颜水成曾在2008年就加入新加坡国立大学,现在也已是新加坡国立大学终身教职;在2011年,颜水成还被新加坡国家科学院授予新加坡青年科学家奖。

颜水成博士是人工智能领域的顶尖专家,尤其专注于计算机视觉、机器学习和多媒体分析。他是ACM院士和新加坡工程院院士。
Sea AI Labs打算吸引人工智能领域的顶尖人才并与之合作,目标是探索和发展与我们现有业务相关的长期见解和技术,以及其他新的机会。颜博士和Sea AI Labs将加强我们在创新和研究方面的能力,以符合我们对推动技术发展的承诺,推动整个地区数字经济的发展。
大佬的工作却遭到Reddit网友的质疑:
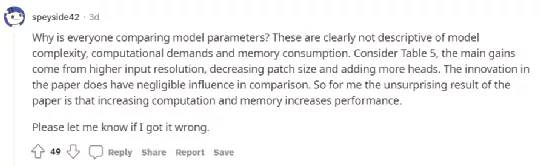
为什么每个人都在比较模型参数?这些显然不能描述模型的复杂性、计算需求和内存消耗。例如表5,主要收益来自更高的输入分辨率,减少补丁大小和增加更多的头。相比之下,本文的创新之处影响不大。所以对我来说,这篇论文的结果并不令人惊讶,那就是计算和内存的增加提高了性能。
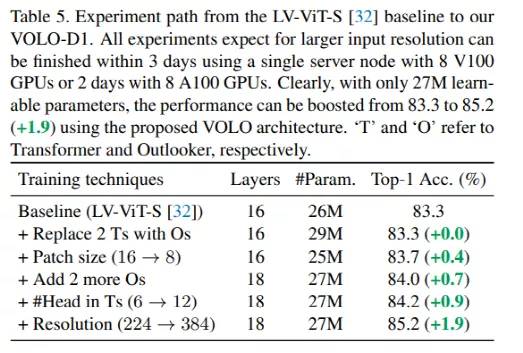
值得一提的是,GitHub上传的代码还特意提到表5中存在一个错误。

从LV-ViT-S[32]基线到我们的VOLO-D1。所有的实验都期望更高的输入分辨率,并且在3天内使用带有8 V100的单个GPU服务器节点2天8 A100 GPU完成训练。显然,文中提出的VOLO架构只有2700万个可学习参数,性能就可以从83.3提高到85.2(+1.9)。“T”和“O”指分别是Transformer和Outlooker。
也有网友认为这不就是CNN的蒸馏吗?

还有网友说arxiv上的论文摘要中有太多的拼写错误,让他感觉对论文的内容很没有信心。网友回复说,这就是预印的意思!
飞鲸投研从多维度分析,整理了一份《成长50》的名单,可以关注同名公众号:"飞鲸投研":feijingtouyan,进行领取(点击复制)















脱水研报
-
此次降准为全面降准,共计释放长期资金约5300亿元。虽然没有明显超预期,但“稳增长”以及稳定宏观经济大盘的预期再次传递给市场。在此背景下,率先受益于降准的房地产
-
指纹密码、面部识别等AI技术正在逐步替代传统的数字密码,但是人们在享受大数据技术进步的同时永远有着对隐私泄露的恐慌。前日,一则关于“人脸数据被公开贩卖”的新闻又
-
我上一篇的文章介绍了处在化妆品行业风口期的丸美股份表现的如此亮眼,是如何抓住行业的红利的。但是,受制于篇幅,我的表述并不完整。今天,让我们继续这个话题。为了抓住
-
现在问题来了,仅通过这张图,我们能推断出中顺洁柔是哪一年上市的吗?答案是2010年。因为这一年中顺洁柔的货币资金占比最高。上市能给企业带来很多好处,比如提升
-
医疗服务产业是大健康产业的核心,这是因为医疗服务驱动着医药和医疗器械的增长和发展,从产业链的角度来看,医疗服务位于产业链下游,是整个大健康产业的核心动力。而医疗




名家观点
-
一隐秀路大佬就是这波主多南天的主力,今天下午又再度拉回,从同花顺超级盘口看它从水下一路点火,要不是大盘太弱了大概率能走出地天,上次也是在一片绝望中隐秀路大佬引导
-
这一周的弱势,始于外资的大幅出逃,不过,周五的弱势,却怪不了人家,参考下北上资金,尽管深港通有一定流出,但也谈不上很大,沪港通更是流入的,所以,周五的弱,纯属于
-
以岭药业:这个票近期是一路小快步上行,到了今天终于是走了加速,明天溢价问题不大,但周四涨停也说明短线资金进来了,短期估计短线资金还会关注这里,明天预计冲高问题不
-
10月份已到了最后几天,三季报也进入到了最后的集中披露,而这个时候,就要注意下不及预期的雷股了。怎么规避不及预期的可能雷股?如果对个股基本面不是很了解,还真没什
-
第二段,就是11点之后,不管是中午前的强反击,还是午后的回落,以及随后的僵持,跟北上资金的节奏几乎完全同步了,这意味着,多空双方都选择了观望,然后,才有了北上资





热点题材
-
点评:根据计划,时速600公里高速磁浮工程样机系统下线后,我国将形成高速磁浮全套技术和工程化能力。未来,通过高速磁浮示范工程建设,进行时速600公里线路运行等相
-
中国中冶(601618)巴新瑞木红土镍钴矿项目已探明的可控镍储量超100万吨;中伟股份(300919)是三元前躯体龙头,定增扩产布局上游资源。
-
车联网产业是汽车、电子、信息通信、道路交通运输等行业深度融合的新型产业形态。当前产业环境下,车联网是国家交通强国战略落地的主要抓手,新基建的主要发展方向之一,发
-
点评:减少碳排放、增加碳吸收是实现碳达峰、碳中和的两大主要方向。碳捕捉位于CCUS全产业链上游,目前依然在成本高、成果小的早期阶段。我国目前仅部署10个全流程
-
激光雷达具有探测距离长、分辨率高、全天候工作等优势,能够有效弥补摄像头、毫米波雷达的感知缺陷,已成为整车厂商宣传智能驾驶的一大卖点。第二代激光雷达技术不但实现了





最新资讯
-
价格的变动反映着背后供求关系的变化,价格回升往往预示着行业景气度的回升,在这个时候,挖掘有潜力的行业和公司尤为重要。我国蛋氨酸现阶段正处于成长期,国产化替代加速
-
从机构调研数量看,排名靠前的迈瑞医疗、联影医疗、澳华内镜,都属于医药行业。汽配行业中,三花智控的关注度是最高的,2023-2024年接待机构近一千家,堪称A股的
-
究其原因,一是大环境推动,二是其下游覆盖领域多,前景广阔。数据显示,2023年中国低空经济市场达到50亿元,预计到2026年将突破万亿。低空飞行与产业融合,是低
-
就在4月27日,“天工”机器人震撼亮相。这是北京人形机器人创新中心推出的产品,由小米机器人、优必选科技等参投。从实际表现看,“天工”机器人并不逊于马斯克的擎天柱
-
其所选投资标的,往往是未来确定性比较高的。数据显示,截至2023年12月31日,在70多家上市中药企中,社保基金一共投资了12家公司。其中,市值现在百亿以上的有