સુપ્રભાત!懂「印度方言」的多语言机翻模型挑战0资源翻译,论文已被ACL2021接收
编辑按:本文转载至微信公众号 “新智元”,贝壳投研经授发布。
多年来,研究人员一直在努力构建一个通用模型,希望可以从任意一个语言翻译到另一个任意的语言。近期,一篇由ACL2021接收的论文或许可以带我们一窥巴别塔之后的世界。
据统计,目前世界上存在的语言超过6900种

《圣经·旧约·创世记》中记载着「巴别塔」的传说:人类联合起来兴建能通往天堂的高塔。
机器翻译的终极使命就是构建人工智能时代的「巴别塔」
 近期,在ACL2021上,字节跳动AI实验室发表了一篇关于多语言机器翻译的论文:Learning Language Specific Sub-network for Multilingual Machine Translation,简称LaSS[1]。
近期,在ACL2021上,字节跳动AI实验室发表了一篇关于多语言机器翻译的论文:Learning Language Specific Sub-network for Multilingual Machine Translation,简称LaSS[1]。

论文:https://arxiv.org/abs/2105.09259
代码:https://github.com/NLP-Playground/LaSS
为了解决多语言机器翻译中最大的挑战之一,即不同语言之间的冲突,论文提出为每个语言对分配专属的子网络从而尽可能减少不同语言对之间的冲突,最终提升模型的表现。
有意思的是,LaSS同时还表现出极强的通用性,能够在保证不影响原来语言对的效果的前提下,在几分钟之内扩展到新的语对并取得相当好的表现。
同时,在最为极端的零样本(zero-shot)的场景下,简单应用LaSS能够大幅提升模型的表现,在30个测试的语言对中获得了平均8.3 BLEU、最高26.5 BLEU的提升。
多语言机器翻译面临的挑战
随着全球化进程不断加快,不同地区之间的交流越发频繁,人们对于利用机器翻译来增进交流的需求越来越强烈。
然而,传统双语机器翻译存在以下几个挑战
传统双语机器翻译只能够将一个语言翻译到另一个语言,对于n个语言之间的互译则需要n×(n-1)个模型,这带来了更大的资源消耗;
一个好的机器翻译模型往往需要大量的平行语料作为支撑,而在现实世界中只有常用语向(如英中、英法等)存在大量平行数据,对于小语种(如英-哈萨克),往往只有少量的甚至没有平行语料。
因此多语言机器翻译应运而生,致力于打造一个能够从任意语言翻译到任意语言的大一统模型。
相比双语机器翻译,多语言机器翻译有如下优势
由于使用一个统一模型,相比传统的双语机器翻译,大大减少了部署的成本消耗;
研究者发现,多语言机器翻译能够显著提升小语种的翻译表现。
然而,多语言机器翻译也面临着重大挑战,其中最大的挑战是语言之间的冲突(language interference)。
由于不同的语言对共享同一个模型,模型的容量不得不被切分,而这往往会导致不同语言对互相争抢更多的模型容量,造成语言对之间的冲突。
直观上看,每个语言都有语言通用(language-universal)和语言专属(language-specific)的特征。
本文提出的LaSS,以神经网络的最小单位即权重(weight)为单位,对于每个语言对LaSS都为它分配一个子网络,该子网络的参数是模型参数的子集。
不同语言对之间共享部分参数的同时,也保留属于自己的参数。通过这种方法,多语言机器翻译就能够实现在一个模型内同时建模语言通用和语言专属的特征。
相比过去的工作而言,LaSS不引入额外的参数。
模型方法
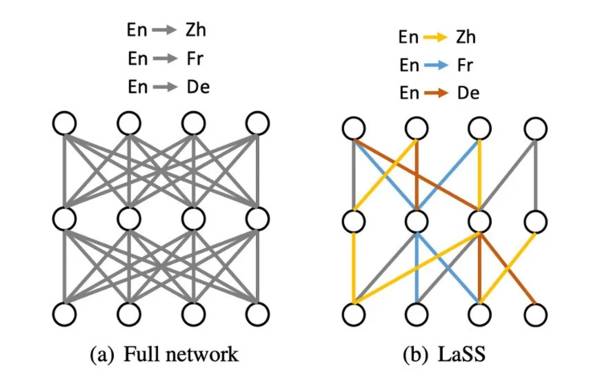
总体架构
左边的图(a)表示传统多语言机器翻译模型,灰色代表共享权重,这意味着,图上三个语言对(En-Zh,En-Fr和En-De)都完全共享同一套参数。
而右边的图(b)则是LaSS,相比(a),三个语言对不仅仅共享部分权重,更重要的是,他们还拥有属于自己的权重(不属于自己的参数为0)。
对于任意一个语言对,网络分配一个子网络,该子网络使用掩码向量(Mask vector)来标明。
也就是说,对于模型任意一个参数,对应的掩码的值为1则表示该语对使用模型对应的权重,相反,当值为0时表示不使用对应的权重。
在训练中,输入语言对的语对,只更新与该语言对相关的子网络,在推理测试阶段,只有与该语言对相关的子网络参与计算。
微调+剪枝生成子网络
本文采用一个简单而高效的方法来找到每个语言对的子网络。
假设已经训练好了一个传统的多语言机器翻译模型,此时在该模型的基础上对某一个语言对进行微调(fine-tune),直观上看,这样的微调会放大对于该语言对的重要的权重,同时会缩小不重要的权重。
在微调后,对微调后的模型的权重进行排序,将值最低的权重进行剪枝。对每个语言对分别进行这样的操作(微调+剪枝),这样就能够获得每个语言对的子网络。
在不同场景不同模型大小下都能获得提升
论文首先在IWSLT上验证LaSS的效果,为了进一步模拟现实世界中数据不平衡的场景,作者还收集了历年的WMT数据集,共组成18个语对36个语向,数据范围从低资源(古吉拉特语,11k)到高资源(法语,37m)。
可以看到,在IWSLT数据集上,LaSS能够获得稳定的提升。

在WMT数据集上,作者选用了不同大小的Transformer,即Transformer-base和Transformer-big。可以看到
在不同大小的Transformer下,LaSS都获得了稳定的提升,其中在Transformer-base上,LaSS的提升较大,这是由于在小模型内语言之间的冲突更严重。
随着数据量的增大,BLEU的提升也增大,这是因为相比低资源的语言对,数据量大的语言对更容易受到语言冲突的影响。
作者添加了随机生成掩码的结果作为对比,验证了LaSS的有效性。
可扩展性表现出色
为了验证LaSS的泛化性能,作者在模型的可扩展性方面做了大量实验。
首先尝试验证LaSS是否能够迅速在新的语对上获得好的表现,同时在现有语对上不下降。作者用微调+剪枝的方法为新语对分配专属的子网络。
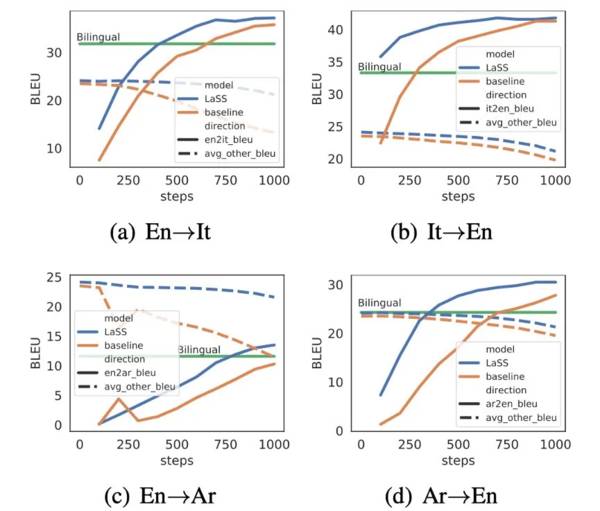
相比多语言基线模型,LaSS表现更优,使用更少的训练步数达到了双语模型的结果;
LaSS在原有语言对的表现下降更平滑。当LaSS在新语对的表现和双语模型持平时,在其他语言对的表现几乎不变,而基线模型则有明显下降的趋势。
这是因为LaSS只选择与该语对相关的参数进行更新,减少了对其他语对的影响,而基线模型更新所有的参数,更容易造成「灾难性遗忘」(catastrophic forgetting)。
零资源翻译场景下能改善目标偏离
零资源翻译(zero-shot translation)指的是模型在训练时从未接触过某个语向的语料,而该语向的两边语言都各自单独出现过。
例如,模型在训练阶段接触过 Fr→En 和 En→Zh 语向的翻译,但没有接触过 Fr→Zh 语向的翻译。
零资源翻译最大的挑战之一是目标偏离(off-target issue) [5],即模型翻译到错误的目标语言。
在前述实验中,由于训练数据是以英文为中心(English-centric)的,因此LaSS并没有非英文为中心(non English-centric)的掩码,作者通过合并 X→En 的编码器掩码和 En→Y 的解码器掩码来创造 X→Y 的掩码。
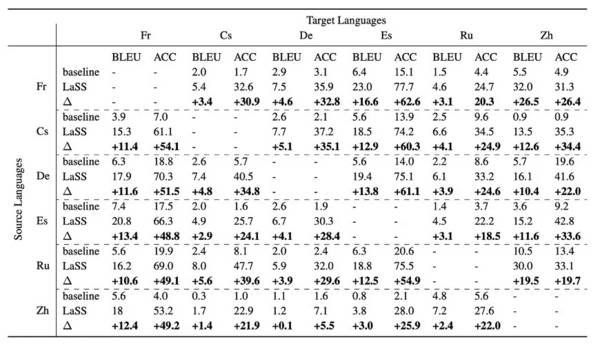
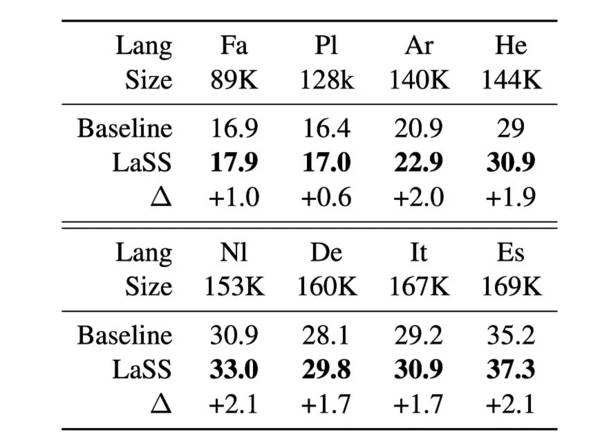
LaSS让各个语言对的BLEU评分都获得极大提升:平均提升8.3BLEU、最高提升26.5 BLEU。
同时在翻译语言的准确性(Translation-language accuracy)也获得了极大的提升,这说明LaSS显著缓解目标偏离的问题。
为了更好地说明LaSS能够缓解目标偏离的问题,作者同时还采样了部分翻译例子。
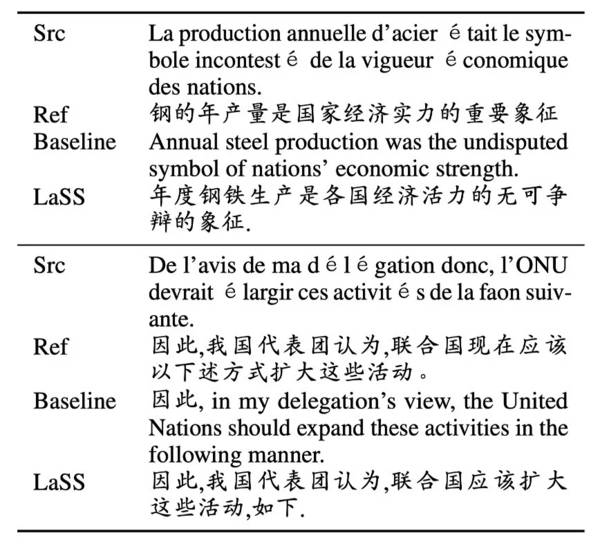
可以看到LaSS极大地改善了翻译语言的准确性,而基线模型翻译的句子虽然意思上是正确的,但翻译到的目标语言则是错误的。
总结
为了解决多语言机器翻译中的语言冲突问题,论文提出了使用LaSS为每个语言对分配专属的子网络。
实验表明,LaSS能够显著缓解语言冲突问题。同时,LaSS还展现出了极强的泛化能力,能够快速适应新的语言对,并且在最极端的零资源翻译场景下,也能够获得极大的提升。
飞鲸投研从多维度分析,整理了一份《成长50》的名单,可以关注同名公众号:"飞鲸投研":feijingtouyan,进行领取(点击复制)
/阅读下一篇/
王兴谈美团优选:“我们对社区电商的长期发展充满信心!”




















脱水研报
-
本周上证综指、深证成指、沪深300分别涨3.39%、涨4.17%、涨3.52%,化妆品板块1涨0.29%,跑输沪深3003.23PCT。板块对比来看,化妆品处行
-
长电科技是全球领先的半导体微系统集成和封装测试服务提供商,提供全方位的微系统集成一站式服务,包括集成电路的系统集成封装设计、技术开发、产品认证、晶圆中测、晶圆级
-
不要让贫穷限制了你的想象力。原来听说有人炒股赚大钱了,人们一脸不屑背地里说人家不务正业,好好的一个人主营业务不做了去炒股赚快钱了。人们能炒股至少表明人家手里
-
(1)团购模式培育基础深厚,迎合本轮升级趋势渠道模式上,公司采用终端前移的方式,缩短厂家与消费者间的距离。在相对减少营销的费用的同时,使得产品能够直达终端消费者
-
事件:公司发布2021 年半年报,实现营业收入 169.52 亿元,同比+20.85%;归母净利润 24.82 亿元,同比+44.77%;扣非归母净利润 15.




名家观点
-
一隐秀路大佬就是这波主多南天的主力,今天下午又再度拉回,从同花顺超级盘口看它从水下一路点火,要不是大盘太弱了大概率能走出地天,上次也是在一片绝望中隐秀路大佬引导
-
这一周的弱势,始于外资的大幅出逃,不过,周五的弱势,却怪不了人家,参考下北上资金,尽管深港通有一定流出,但也谈不上很大,沪港通更是流入的,所以,周五的弱,纯属于
-
以岭药业:这个票近期是一路小快步上行,到了今天终于是走了加速,明天溢价问题不大,但周四涨停也说明短线资金进来了,短期估计短线资金还会关注这里,明天预计冲高问题不
-
10月份已到了最后几天,三季报也进入到了最后的集中披露,而这个时候,就要注意下不及预期的雷股了。怎么规避不及预期的可能雷股?如果对个股基本面不是很了解,还真没什
-
第二段,就是11点之后,不管是中午前的强反击,还是午后的回落,以及随后的僵持,跟北上资金的节奏几乎完全同步了,这意味着,多空双方都选择了观望,然后,才有了北上资





热点题材
-
点评:中国北斗卫星导航系统是中国自行研制的全球卫星导航系统,也是继GPS、GLONASS之后的第三个成熟的卫星导航系统,随着5G商用时代的到来,北斗正在与新一代
-
机构分析指出,国内新能源汽车IGBT模块市场中,海外企业占据垄断地位,其中英飞凌市占率达到58.20%。国内企业近年成功在国内新能源汽车用IGBT模块市场中占取
-
点评:CAR-T是目前T细胞免疫疗法癌症治疗领域的“新宠”,被誉为肿瘤终极疗法。国外权威机构预测,随着干细胞、免疫细胞以及其他体细胞治疗技术在各种再生医学、肿瘤
-
在成本优势和安全性能的优势下,磷酸铁锂动力电池出货量今年5月和6月连续两个月超过三元电池,重回“王座”。受益于汽车产业电动化的变革,产业链享受超高景气度,机构预
-
点评:由于石墨烯拥有超乎想像的导电能力,石墨烯电池概念成为突破电池技术瓶颈的救命稻草。尤其国内电动汽车行业但凡有技术突破大都与石墨烯电池挂钩。 锦富技术(30





最新资讯
-
继盐津铺子“低成本上的高品质+高性价比策略”转型、良品铺子主动降价后,三只松鼠的高端性价比策略也显现出成效,这也将本轮流量型企业的商业模式变革引向高潮。正所谓富
-
关于银发经济的内涵,其实就是为向老年人提供产品或服务,以及为老龄阶段做准备等一系列经济活动的总和。具体来看,这个“银发经济”包含了“老年阶段的老龄经济”和“未老
-
以低PE高分红为代表的江中药业、云南白药、白云山、东阿阿胶、新和成、丽珠集团、迈瑞医疗持续实现“价值回归”;以业绩增长为导向的公司强者恒强,艾力斯、海思科、川宁
-
但过去的经验告诉我们,大基建不能瞎搞乱建,图一时之快而造成资源浪费,最终形成一堆建筑垃圾。目前,在可选择的范围内,更新国内的地下管网是性价比比较高的基建投资,而
-
2024年开年以来,随着各地举措落地,低空经济热度居高不下,五一假期之后,低空概念再次起势,成为如今市场最大的看点之一。作为低空飞行最基础也是最重要的载体——e