苹果公司华人研究员抛弃注意力机制,史上最快的Transformer!新模型达成最低时间复杂度
2017年,一篇神奇的论文Attention is All You Need横空出世,目前已有两万多个引用,为后续的BERT,GPT类模型提供了基础的Transformer模型,在NLP,CV等多个机器学习领域大放异彩。
Transformer中一个重要的机制就是注意力(Attention),这也是论文标题中重点说明的,也是效果好的原因。
但谷歌的老对头苹果公司不这么想,近日,苹果公司在arxiv上上传了一篇论文,无需注意力机制的Transformer,即Attention Free Transformer (ATF)。

第一作者为华人Shuangfei Zhai,是毕业于宾汉姆顿大学的博士。
在attention效果好的时候,重新回顾不采用attention的研究方法就成了创新
论文的摘要中说明,AFT是Transformer的一个有效的变体,不再需要自注意力机制。
一个 AFT 层中,key和value首先与一组已学习的位置偏差组合在一起,其结果以元素级(element-wise)方式与query相乘。
这种新的操作具有记忆线性复杂度(上下文大小和特征维度),使其既能兼容长输入文本,也能平衡模型大小。

AFT这个基础模型在文中又称为AFT-full,可视化的结果如下所示。对于每个时间步t来说,AFT都是value的加权平均值,结果就是和query的element wise的乘法。
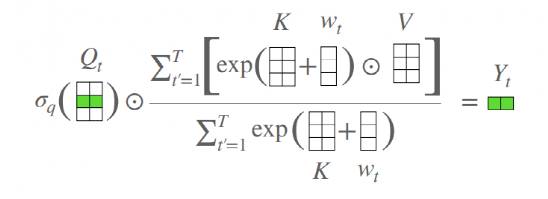
除此之外,文中还介绍了 AFT-local 和 AFT-conv 两种模型,它们利用了局部性和空间权重分配的思想,同时保持了全局连通性。
AFT-local主要借鉴了CNN的思想,把相邻二维attention矩阵给平均池化

AFT-simple是AFT-local的一个特殊情况,当s=0的时候,也就是没有位置偏差
AFT-conv学习到了相邻位置的偏差,也是从局部性的想法扩展而来,采用了空间查权重共享的想法,也就是卷积,这个模型对于视觉相关的任务来说特别好用。
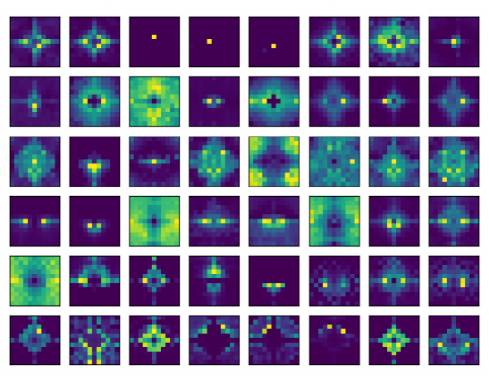
这个模型在两个自回归建模任务(CIFAR10和 Enwik8)和一个图像识别任务(ImageNet-1K 分类)上进行了广泛的实验,证明了 AFT 在所有的基准测试中都表现出了很好的竞争性能,同时也提供了很好的效率。
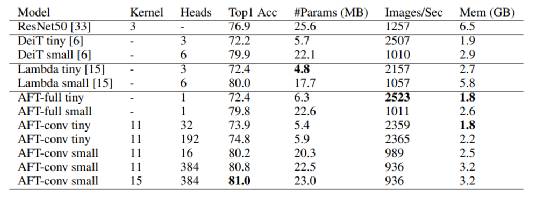
论文的结论就是AFT取代了原有attention机制中的点乘运算,并且在数据集上取得更好的结果,并且时间复杂度明显降低,这项工作将为Transformer类的模型提供参考。
论文在reddit社区上引发了激烈的讨论,有网友表示,你不需要卷积,你不需要注意力机制,你什么都不需要,能不能告诉我们到底需要什么?

有人回复道,我们需要价值数百万美元的硬件设备。
还有说全连接层is all you need
即将到来的下一篇文章:Nothing is all you need。
编辑按:本文转载至微信公众号 “新智元”, 贝壳投研经授发布
飞鲸投研从多维度分析,整理了一份《成长50》的名单,可以关注同名公众号:"飞鲸投研":feijingtouyan,进行领取(点击复制)
/阅读下一篇/
菜鸟码农一入行就拿百万年薪?2021硅谷巨头晒出霸气工资单!




















脱水研报
-
倍轻松成立于2000年,主要从事智能便携按摩器的设计、研发、生产、销售及服务,产品包括颈部、眼部、头部等部位的按摩器具,在行业内处于领导地位。据浙商证券研报分析
-
营销能力不强,员工积极性不高在过去长期制约着汾酒的发展。2017年李秋喜董事长签订目标责任书之后,汾酒销售公司作为改革排头兵率先开启大刀阔斧的改革。随后提出以市
-
今天想说点不一样的,主要是看到近几日煤炭有色等周期板块在国家政策管控之下消停了不少,煤炭的市场炒作成为了原罪。但与煤炭行业相关又对立的电力板块波动却没有那么明显
-
核心观点:士兰微是国内IDM 模式的功率龙头,具有外延片制造、晶圆制造和封测产线。IDM 能保证产能的持续供应,配合客户做定制化开发,缩短开发周期,享有晶圆代工
-
芯朋微是小家电电源管理芯片细分龙头,在美的、格力等国内一线家电厂商深受认可。今年以来,公司大家电芯片开始进入大批量量产,为公司开启新的增长引擎。据国元证券研报分





名家观点
-
一隐秀路大佬就是这波主多南天的主力,今天下午又再度拉回,从同花顺超级盘口看它从水下一路点火,要不是大盘太弱了大概率能走出地天,上次也是在一片绝望中隐秀路大佬引导
-
这一周的弱势,始于外资的大幅出逃,不过,周五的弱势,却怪不了人家,参考下北上资金,尽管深港通有一定流出,但也谈不上很大,沪港通更是流入的,所以,周五的弱,纯属于
-
以岭药业:这个票近期是一路小快步上行,到了今天终于是走了加速,明天溢价问题不大,但周四涨停也说明短线资金进来了,短期估计短线资金还会关注这里,明天预计冲高问题不
-
10月份已到了最后几天,三季报也进入到了最后的集中披露,而这个时候,就要注意下不及预期的雷股了。怎么规避不及预期的可能雷股?如果对个股基本面不是很了解,还真没什
-
第二段,就是11点之后,不管是中午前的强反击,还是午后的回落,以及随后的僵持,跟北上资金的节奏几乎完全同步了,这意味着,多空双方都选择了观望,然后,才有了北上资





热点题材
-
另有业内人士透露,电网规划专家初步建议,“十四五”期间规划的特高压工程数目在16条左右,以直流线路为主,主要负责输送新能源,助力实现“双碳”目标。电网投资一直是
-
国家能源局将会同工业和信息化部年内研究出台《关于进一步提升充换电基础设施服务保障能力的实施意见》,从加强规划布局、移动居住社区充电桩安装、加强设备运维、提高供电
-
中海油服(601808)、海油工程(600583)、海油发展(600968)等。
-
点评:汉信码由中国物品编码中心牵头自主研制,是拥有完全自主知识产权的二维码码制,达到国际领先水平。汉信码实现了我国二维码底层技术的后来居上,可在我国多个领域行
-
点评:国际权威机构Statista的分析,2020年全球数据产生量预计47ZB,随着新兴技术的快速发展,预计2035年全球数据量将增至2142 ZB,年复合增速





最新资讯
-
继盐津铺子“低成本上的高品质+高性价比策略”转型、良品铺子主动降价后,三只松鼠的高端性价比策略也显现出成效,这也将本轮流量型企业的商业模式变革引向高潮。正所谓富
-
关于银发经济的内涵,其实就是为向老年人提供产品或服务,以及为老龄阶段做准备等一系列经济活动的总和。具体来看,这个“银发经济”包含了“老年阶段的老龄经济”和“未老
-
以低PE高分红为代表的江中药业、云南白药、白云山、东阿阿胶、新和成、丽珠集团、迈瑞医疗持续实现“价值回归”;以业绩增长为导向的公司强者恒强,艾力斯、海思科、川宁
-
但过去的经验告诉我们,大基建不能瞎搞乱建,图一时之快而造成资源浪费,最终形成一堆建筑垃圾。目前,在可选择的范围内,更新国内的地下管网是性价比比较高的基建投资,而
-
2024年开年以来,随着各地举措落地,低空经济热度居高不下,五一假期之后,低空概念再次起势,成为如今市场最大的看点之一。作为低空飞行最基础也是最重要的载体——e