中科院出手,1000亿参数全模态大模型发布,能看懂视频、绘画作曲、分析信号
编辑按:本文转载至微信公众号“智东西”,飞鲸投研经授发布 。
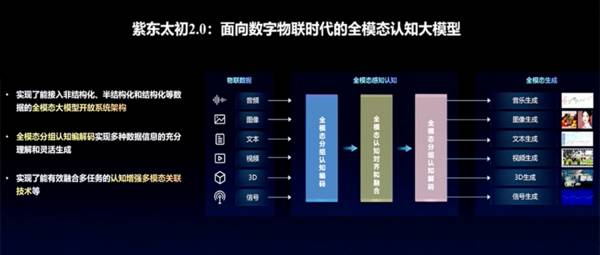
智东西6月16日报道,在今日举行的人工智能框架生态峰会2023上,中国科学院自动化研究所所长徐波正式发布紫东太初2.0全模态大模型。

相比以前的大模型,紫东太初2.0新增了视频、传感信号、3D点云等模态,拥有了更强的认知、理解、创作能力。
它不仅有和ChatGPT类似的多轮问答、文本创作能力,还实现了全模态输入,支持视频、图像、音乐、3D、信号的理解,并能够实现图文音搜索、图像生成、音乐生成、信号分析等功能。
智东西拿到了内测资格,并第一时间对紫东太初2.0的音乐能力、信号类能力、视频能力、跨模态能力、图像能力、语言能力等进行体验。
01.五大能力详解,从生成音乐、看懂视频到推理分析
1、音乐及信号类能力:生成、识别、多模问答
紫东太初2.0可以通过给定的文本提示,可控生成高保真的音乐,并支持即兴创作多种风格类型和多种乐器演奏的音乐。
比如,上传一段音乐文件,让紫东太初2.0识别这个音乐是什么,它能识别出这是贝多芬的交响曲,并分享了这段音乐表达了怎样的感情。

你还可以询问这段音乐是用什么乐器演奏的,让紫东太初2.0根据这段音乐作诗,或者追问贝多芬的生平是怎样的。
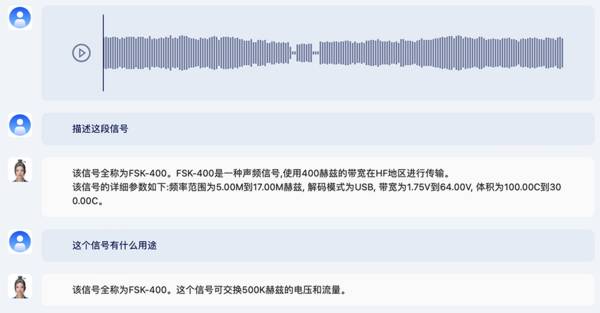
紫东太初2.0也支持雷达信号鉴别与知识交互,可借助模型快速掌握信号基本来源及参数等。
上传一段信号后,你可以向它询问这段信号的相关信息。
2、视频能力:理解、描述、搜索
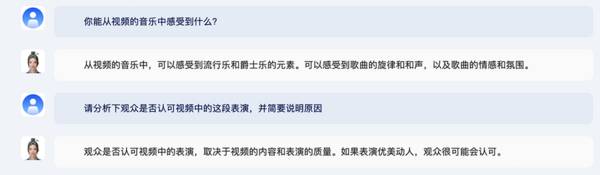
视频能力方面,紫东太初2.0能基于用户上传的视频素材,准确理解并回答视频识别、视频描述类问题,同时支持上下文信息理解和多轮问答。
比如,上传一段唱歌跳舞的视频,问紫东太初2.0这段视频描述了什么、对视频中音乐的感受、是否认可等问题。

此外,紫东太初2.0拥有海量的高质视频素材库,具备视频素材检索能力。
比如让它找一个踢足球的视频。
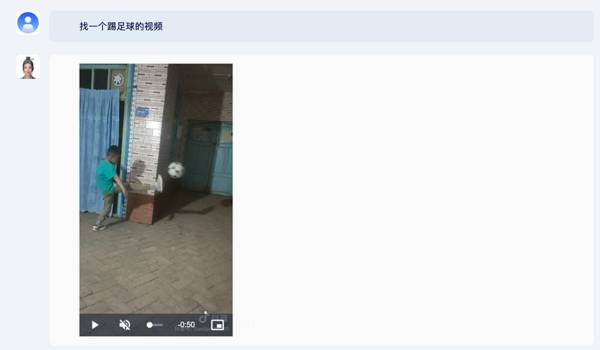
你还可以针对视频内容进一步发问,让紫东太初2.0结合动作和音乐分析视频,或是根据视频内容预测后面可能发生什么事。

3、跨模态能力:“图像+音频+视频”理解与分析
紫东太初2.0能结合多个图像、音频、视频文件,进行综合理解与创作。
上传两个视频,问这两个视频的共同特点是什么?对此,紫东太初2.0能够结合视频的画面和声音,分析出共通之处以及各自的差异点。

另一个例子是图像+音频。
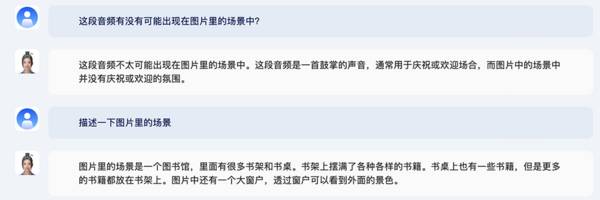
上传一张图书馆的图片和一段鼓掌声音频,问这段音频有没有可能出现在图片里的场景中?

紫东太初2.0给出答案:不太可能,原因是图片中的场景没有庆祝或欢迎的氛围。
或者,上传一张足球场的图片+一段鼓掌声音频,让紫东太初2.0结合图片和音频,分析一下场景的氛围。


通过综合理解图像、音频、视频信息,紫东太初2.0“拼出”一个完整的信息描述,或者将这些内容串联形成一段流畅的故事。

4、图像与3D场景能力:描述、目标检测、检索、生成
紫东太初2.0能基于用户上传的图片素材,准确理解并回答图片识别类问题,包括识别图像主体、背景、动作、颜色等等,同时支持上下文信息理解和多轮问答。
比如问“图里有几只动物”、“小狗和小猫在做什么”,紫东太初2.0给出了具体的描述。
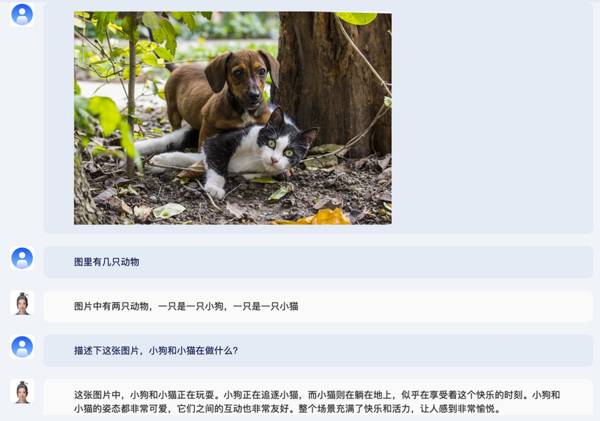
你还可以针对这张图片,询问更多细节,比如小动物的毛色、它们在什么地方玩。

上传风车的图片,问“这个装置的作用是什么”,紫东太初2.0给的回答包括“风力发电站”。

接着追问“为什么要在图中位置建设这样的装置”,它马上给出回答:“为了让它更加接近自然环境,以便更好地利用风能。”

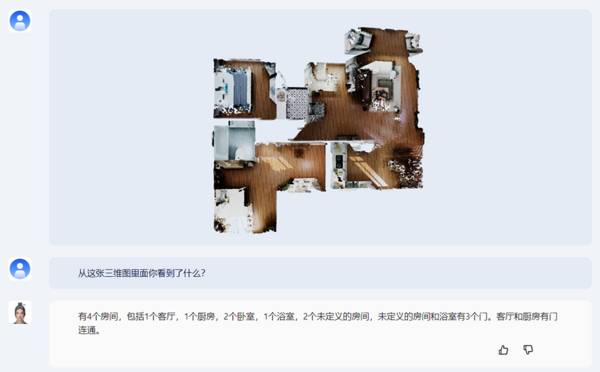
此外,紫东太初2.0具备基于点云数据的3D场景理解和物体感知能力。你可以让它描述从这张三维图里看到了什么信息。
不过在理解梗图方面,紫东太初2.0的能力还没有开发出来,并不能弄明白下图好笑在哪儿。


除了搜视频,紫东太初2.0也能被用于搜图。比如让它生成一张熊猫的图片。

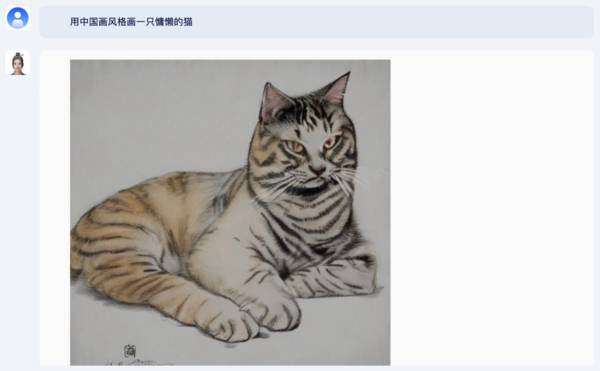
在生成图像方面,紫东太初2.0可以生成指定风格的图。比如我要求“用中国画风格画一只慵懒的猫”,紫东太初2.0立刻画出了一张卧着的虎皮猫。
5、语言与编程:问答、创作、查错、写代码
在语言能力方面,和多数大型语言模型一样,紫东太初2.0支持中文问答、逻辑推理、文本摘要、文本续写、文本创作、标题生成、语法分析、机器翻译等等。
它能准确理解用户输入的问题语境,并能做出准确的知识性问答,包括生活常识、工作技能、医学知识、历史人文等知识领域。

给紫东太初2.0一篇文章,它能快速理解文章的核心观点,根据长文本提取简洁而准确的摘要。

它也能写一个拥有出人意料结局的推理小说。

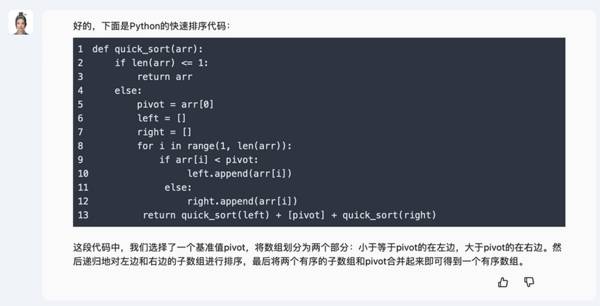
写个快速排序代码,同样不在话下。
综合来看,紫东太初2.0在图文音多模态能力的基础之上,增加了对视频、3D场景和信号等模态的理解,用更多模态信息来弥补单模态的局限性,更好地增强了对多种模态的综合理解和认知。
02.突破多项多模态关键技术,完成跨模态对齐
徐波说,中科院早在2008年就开始推进图文音的单独攻关,2020年1月启动多模态联合攻关,从2021年1月做出百亿模型到2021年9月发布全球首个千亿参数图文音三模态大模型紫东太初1.0,再到推出紫东太初2.0,以昇腾AI硬件及昇思MindSpore AI框架为基础,依托武汉人工智能计算中心算力支持,利用预训练+微调技术,在大的神经网络上,把多个场景的知识和数据都吸纳到一个模型上。

但物理世界的信息种类远多于图文音,有大量结构化、半结构化、非结构化数据,包括温度、深度、压力信号、3D超声波指纹、脉搏波、降水量、人体红外、3D激光等等诸多形式。

基于这样的认识,面向数字物联时代,紫东太初2.0推出实现了能接入非结构化、半结构化、结构化等数据的全模态大模型开放系统架构。
面对全模态数据,紫东太初2.0率先实现了认知增强的多模态关联,在全模态理解能力、生成能力、对齐能力上实现了跃升。
研究团队重点研究突破了多模态分组认知编码、全模态认知对齐和融合、多模态分组认知解码等关键技术,使多模态关联的认知能力大幅提高。
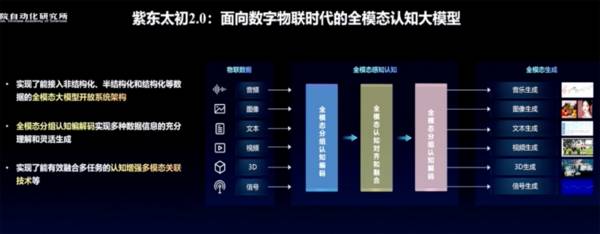
通过完成音乐、图像、视频等数据之间的跨模态对齐,紫东太初2.0可处理音乐视频分析、三维导航等多模态关联应用应用需求,并可实现音乐、视频等多模态内容生成。
由此,紫东太初2.0打通了感知、认知乃至决策的交互屏障,具有全模态能力的涌现,使得人工智能进一步感知、认知世界,从而延伸出更加强大的通用能力。
03.落地进展:助攻颅内手术,研判违规行为,溯源敏感信息
徐波说,紫东太初底座大模型正赋能千行百业,包括布匹纺织及缺陷检测、文旅导游、柔性手术机器人、AI手语老师等。

例如在医疗场景,基于紫东太初打造的颅内手术多模态智能助手可实现不同模态的高效协同与转换,尤其是视觉、触觉的跨模态融合,解决了机器人辅助手术中触觉缺失的国际性难题。
协和医院用到紫东太初2.0在全模态方面的推理功能,去尝试在医疗诊断方面做一些有挑战性的工作,尤其是在心、脑、肾三个罕见病中,利用多种医疗模态和患者病例特点,生成拟诊讨论,在诊断、鉴别诊断和治疗计划给出一些建议。
在交通场景,以前智能系统更多关注识别到比较常见的交通违规行为,但实际场景中会有很多细碎的违规行为,比如压实线、摩托车不戴头盔、三轮车违法载人等等。只需输入对违规行为的文字描述,再给1~2张图片,紫东太初就能实现对违规行为认知级别的研判。
在互联网短视频场景中,有些短视频的标题和简介文本没有问题,但视频内容包含敏感信息。利用多模态融合感知技术,可以对视频进行溯源,及时发现风险内容。
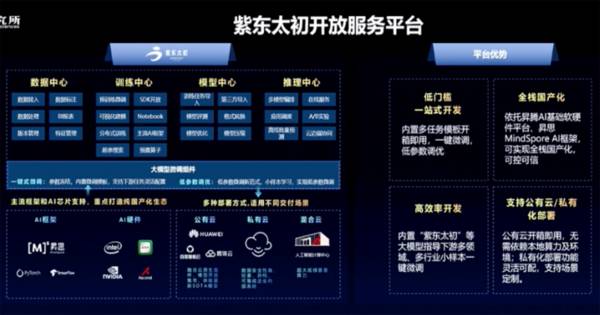
在大模型的基础上,中科院也研发了紫东太初开放服务平台,以惠及更多用户。
04.结语:迈向通用人工智能的三条路径
徐波说,大模型成为人工智能发展的里程碑和分水岭,以ChatGPT为代表的“大算力+大数据+大模型”标志着通用人工智能时代的来临,大模型将实现对劳动力、资本等生产要素的智能替代和功能倍增,促进全要素生产率的提高。
人类的学习和交互过程中充满了多模态信息,包括自然语言、视觉、听觉、触觉、嗅觉/味觉、生理信号等等。以婴儿早期发育为例,它通过多种模态信息可以很容易地感知和学习世界,基于这一认识,紫东太初大模型从一开始走的就是多模态技术路线。
据徐波分享,通过可自主进化通用人工智能有三条路径:类脑智能、信息智能、博弈智能。
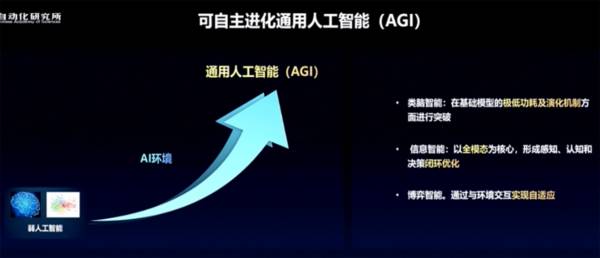
他认为,目前全模态的信息智能走得更快,但它一定会吸纳类脑智能在极低功耗及演化机制方面的优势,也一定会吸纳博弈智能与环境交互产生自适应能力的机制,融合起来,才是更强的通用人工智能。
飞鲸投研从多维度分析,整理了一份《成长50》的名单,可以关注同名公众号:"飞鲸投研":feijingtouyan,进行领取(点击复制)
/阅读下一篇/
Meta生成式AI竞赛下一站:让开发者靠开源大模型挣钱






















脱水研报
-
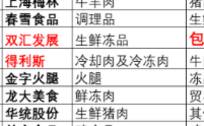
但是从公司公告的发布时间看,花巷股份像是抄作业的那位学生。下面截图为证。2021年10月28日新希望在《公开发行可转换公司债券募集说明书》提到:低温肉制品具有鲜
-
公司作为国内男装行业龙头企业,全面发展多元品牌矩阵,以期实现“服饰生活零售集团”的战略转型。据中银证券研报分析,公司持续推进品牌多元化年轻化转型,预计随着疫情恢
-
时间创造复利的价值。关于时间和复利的关系,下面这张图表达得很明了。 对投资而言,好公司是时间馈赠给投资者最好的礼物;对个人而言,时间是生命中比金钱更重要的东西。
-
01差不多了毫无意外,又是一记重锤,不过今天盘中却出现了深V的走势。在交流中,老张上午快收盘,提示大家要把握差价机会,下午大盘短暂翻红后又继续下探,底部是个
-
最近在看白酒,翻一翻各大头部酒企的财报,学习一下“股价始终在涨的企业都是怎样炼成的”。翻到白酒老二五粮液的各年财报时,一个细节引起了我的注意。2019年公司13



名家观点
-
一隐秀路大佬就是这波主多南天的主力,今天下午又再度拉回,从同花顺超级盘口看它从水下一路点火,要不是大盘太弱了大概率能走出地天,上次也是在一片绝望中隐秀路大佬引导
-
这一周的弱势,始于外资的大幅出逃,不过,周五的弱势,却怪不了人家,参考下北上资金,尽管深港通有一定流出,但也谈不上很大,沪港通更是流入的,所以,周五的弱,纯属于
-
以岭药业:这个票近期是一路小快步上行,到了今天终于是走了加速,明天溢价问题不大,但周四涨停也说明短线资金进来了,短期估计短线资金还会关注这里,明天预计冲高问题不
-
10月份已到了最后几天,三季报也进入到了最后的集中披露,而这个时候,就要注意下不及预期的雷股了。怎么规避不及预期的可能雷股?如果对个股基本面不是很了解,还真没什
-
第二段,就是11点之后,不管是中午前的强反击,还是午后的回落,以及随后的僵持,跟北上资金的节奏几乎完全同步了,这意味着,多空双方都选择了观望,然后,才有了北上资
热点题材
-
兴业证券认为,此次Model Y价格首次下探至30万元以内,这是宝马X1/奥迪Q3等豪华品牌入门SUV的主力价格区间,将进一步凸显特斯拉竞争力,未来销量或超预期
-
点评:行业估计,三星电子此番或炒热全球折叠屏智能手机市场,目前多家市场调研机构纷纷上调了市场预期。DSCC日前变更今年全球折叠屏智能手机面板出货量为1038.8
-
点评:车载AI芯片是人工智能行业的珠穆朗玛,也是自动驾驶实现大规模落地的前提。不少企业纷纷布局,这其中就包括特斯拉和英伟达,而在国内企业方面,地平线走在最前列。
-
东吴证券认为,“十四五”时期,电化学储能作为支撑能源转型的关键技术,将呈现高速发展态势。机构统计,2020年国内电化学储能新增投运规模达1.56GW,首次突破G
-
中金公司认为,中央对节水社会建设的统筹安排将促进水资源项目建设,水处理行业有望受益,智慧水务、污水资源化等细分板块也将迎来发展机遇。威派格:打通了从水源地、水厂





最新资讯
-
究其原因,一是大环境推动,二是其下游覆盖领域多,前景广阔。数据显示,2023年中国低空经济市场达到50亿元,预计到2026年将突破万亿。低空飞行与产业融合,是低
-
就在4月27日,“天工”机器人震撼亮相。这是北京人形机器人创新中心推出的产品,由小米机器人、优必选科技等参投。从实际表现看,“天工”机器人并不逊于马斯克的擎天柱
-
其所选投资标的,往往是未来确定性比较高的。数据显示,截至2023年12月31日,在70多家上市中药企中,社保基金一共投资了12家公司。其中,市值现在百亿以上的有
-
跨国药企为全球创新药企蹚出一条路,原来药王不仅出现在肿瘤和自免领域,内分泌(代谢)也是孕育重磅药的摇篮。诺和诺德的司美格鲁肽仅用6年时间就突破了200亿美元的年
-
当一个国家65岁及以上老年人口,占总人口比例超过7%时,就意味着进入了老龄化。2023年,我国65岁及以上人口数量2.17亿人,在总人口中占比15.4%。随着生